一. 图像语义分割
传统的图像分割方法主要包括以下几种:
1)基于边缘检测
2)基于阈值分割
比如直方图,颜色,灰度等
3)水平集方法
这里我们要说的是语义分割,什么是语义分割呢?先来看张图:

将目标按照其分类进行像素级的区分,比如区分上图的 摩托车 和 骑手,这就是语义分割,语义分割赋予了场景理解更进一步的手段。
我们直接跳过传统的语义分割方法,比如 N-Cut,图割法等,直接进入深度学习。
二. FCN 的引入
CNN 在图像分割中应用,起源于2015年的这篇影响深远的文章:
Fully Convolutional Networks for Semantic Segmentation 【】
这里提到的就是全卷积网络,那么这个全卷积是如何理解 和 Work 的呢?来看一个对比:
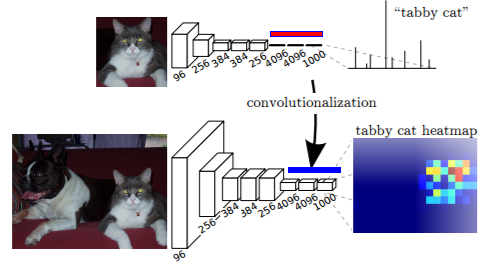
上图红色部分 对应CNN分类网络的最后三层,也就是 FC 全连接,通过 Softmax 得到一个1000维的向量(基于Imagenet的图像分类),表示1000个不同的分类对应的概率,“tabby cat” 作为概率最高的结果。
下图蓝色部分将 分类网络对应的最后三层全连接 替换成了 卷积。整个网络全部通过卷积连接,so called 全卷积。这么做的目的是什么呢?
● 通过像素分类来定义语义分割
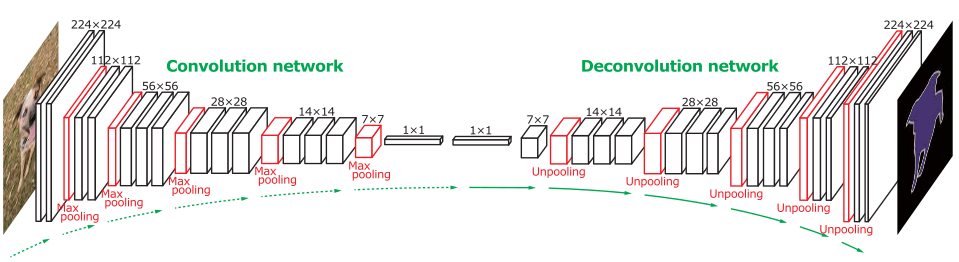
全卷积网络的输出是一张分割图,如何输出这张分割图呢? 通过卷积,图像的分辨率逐渐降低,这里需要 引入一个概念,就是上采样,即将低分辨率的图像放大到和原始图像同分辨率上,这是一个关键点。比如经过5次卷积(pooling)后,图像的分辨率依次缩小了2,4,8,16,32倍。对于最后一层的输出图像,需要进行32倍的上采样,得到原图大小一样的图像。
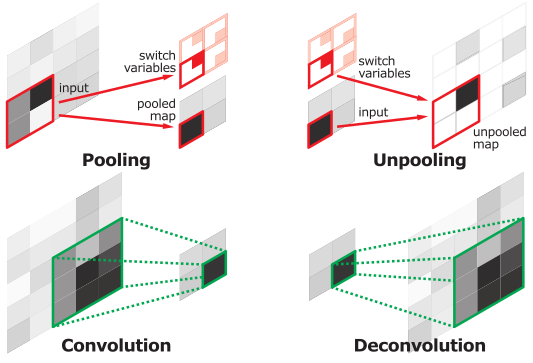
这个上采样是通过 反卷积(DeConvolution)实现的。来直观看一下反卷积的过程:
加上反卷积过程,整个的网络可以描述成:
由于前面采样部分过大,有时候会导致后面进行反卷积得到的结果分辨率比较低,导致一些细节丢失,解决的一个办法是 将 第 3|4|5 层反卷积结果叠加,结果我们就不贴了,肯定是上采样倍数越小,结果越好,来看叠加示意图(这种方式应该不陌生):
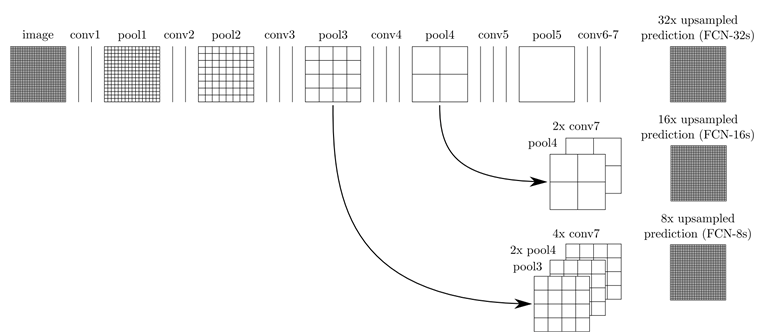
三. FCN 的改进
虽然 FCN引领了CNN基于语义分割的方向,但仍有很多地方需要改进,比如上采样导致的像素分割不精细,效率也不够快等等,我们相信一定有办法让其 更高效、更精细。这里提到的一个 方法就是结合 CRF。
CRF 全称是 Conditional Random Field,中文叫 “条件随机场”,首先来理解什么是随机场,一堆随机的样本就可以理解为是随机场,假设这些样本之间有关联关系,就成立条件随机场,CRF 最早在深度学习的 NLP 领域有比较多的应用,可以理解为语境的上下文关系,可以参考下面这篇文章:
第一个改进 来自于 UCLA 的 Liang-Chieh Chen,在像素分类后叠加了一个 Fully Connected Conditional Random Fields(全连接的条件随机场)。
论文地址:
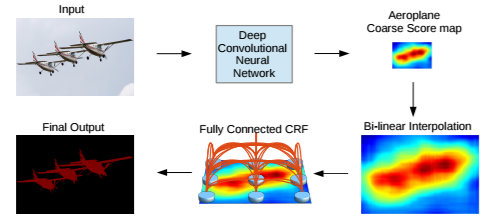
通过上图示意可以看到,Fully Connected CRF 在前面 FCN 输出的基础上,以全连接的形式,实现了后处理过程,使得像素分割更加细致,具体请参考论文。
接下来的改进有 通过 RNN + CRF 的idea:
参考论文:
根据实验对比效果来看,相当不错(注:DeepLab 就是上面的 Full connected CRF方法):

针对FCN的改进会在近两年一直持续,作者最关注的还是,Mask-RCNN,将目标检测与分割一起work的方法,接下来在下一篇文章介绍!
“桃李不言,下自成蹊”,FCN 当真是属于这个级别的贡献,引领了在这条道路上的每一次Follow。
四. 实例分割(Instance Segment)
实例分割 与 语义分割的区别是要区分出每个目标(不仅仅是像素),相当于 检测+分割,通过一张图来直观理解一下:
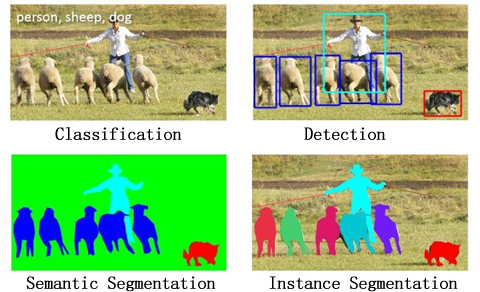
关于 实例分割 的一篇典型论文 MaskRCNN,可以参考【】,代码实现可以参考【】
相关论文:
Instace-sensitive Fully Convolutional Networks.ECCV 2016【】
R-FCN:Object Detection via Region-based Fully Convolutional Networks.NIPS 2016【2016.7月上传到arxiv】
Fully Convolutional Instance-aware Semantic Segmentation.xxxx 2017【2016年11月上传到arxiv,MSCOCO2016的第一名】